雲南(nán)邁勝教育咨詢有(yǒu)限公司
誠信利他(tā),服務至上(shàng),專業(yè)高↑¥(gāo)效

結構方程模型建模思路(lù)及Amos操作(zuò)
作(zuò)者:雲南(nán)邁勝文(wén)教 日(rì)期:2021-02-18 20:09:46
相(xiàng)信為(wèi)什(shén)麽要(yào)選擇結構方程模型分(fēn)析數(sβ≤×hù)據,大(dà)家(jiā)心裡(lǐ)面是(shì)有(yǒu)B數(sγ♣hù)的(de),所以我就(jiù)不(bù)說(s♥↔¥✘huō)了(le)。
一(yī)般而言,利用(yòng)SEM分(fēn)析✔₹的(de)數(shù)據來(lái)源于問(wèn)卷調查,當然也(yě)可(k♠™₩☆ě)以用(yòng)其他(tā)的(de)觀察變量直接進行(xíng)分 ©(fēn)析,比如(rú)說(shuō)在經濟領域建模,類似于資本、人≈♠(rén)力、投資等是(shì)可(kě↓↑☆✘)以直接觀察的(de),不(bù)需要(yào)引入潛在變量,∏≈所以也(yě)不(bù)需要(yào)問(wèn)卷進行♥(xíng)數(shù)據收集,一(yī)般是(shì)有>∑♥(yǒu)數(shù)據庫這(zhè)樣子(zǐ)的(ε₩"de)。
問(wèn)卷設計(jì)的(de)時(shí)候,有(yǒu)一(yīδ®₩)些(xiē)小(xiǎo)技(jì)巧
1.設計(jì)量表的(de)時(shí)候,顆粒度分(fēn)細一(yī)些(♠Ω∏xiē),最好(hǎo)的(de)李克特7級量表(Lubke & Muthén, 2004)。别π£看(kàn)國(guó)內(nèi)大(dà)家(jiā)平時(shí)都(Ω∏dōu)是(shì)用(yòng)的(de)≥♠<李克特5級量表多(duō)一(yī)些(xiē),其實 ←在SEM軟件(jiàn)分(fēn)析的(de)時(shí)候,國(guó)外(wài)使用(≥↓"yòng)5級或者7級的(de)量表進行(xíng→ )數(shù)據收集的(de)paper都≠♥(dōu)比較多(duō)。并且,顆粒度越細,數(shù)據越≈♦∏容易服從(cóng)多(duō)元正太分(fēn)布,才能(né☆✔♥ng)采用(yòng)SEM內(nèi)定的(de)ML進行(xíng)數(shù)據分(f™≈↑ēn)析。但(dàn)是(shì)記住,5級量表是(shì)最低(dī)要(>∑♥yào)求,不(bù)能(néng)更低(dī)了(le)。
2.萬一(yī)沒辦法,你(nǐ)拿(ná)到(dào)的(de)數(shù)據離(lí)散程度較差γ•∑,成偏态,或者是(shì)見(jiàn)下(xià)圖,二分(fēn)∞"₩類變量啊親,搞死人(rén)的(de)情況下(xià),可(kě)以采用€≥♦(yòng)Item parcel的(de)方法,就(jiù)是(shì)打包的(de)意思,你(nǐ)按照(zh₩ ào)自(zì)己的(de)專業(yè)知(zhī)識,如(rú)果問(wèn)卷題目>∞♥夠多(duō)話(huà),把好(hǎo)幾道(dào)題的(de)結果相(♦★♦xiàng)加,即使樣本上(shàng)不(bù)大(dà),達到(dào)一(∞¥yī)定穩定性,如(rú)果樣本量較大(dà),也(yě)可(kě)以解決這(zhè)種無 ₽奈的(de)問(wèn)卷設計(jì)缺陷。
這(zhè)本書(shū)Kenny D A. Correlat≠&ion and causality.[M]// Cor®¥relation and causality. Wiley, "1979:e140-1.裡(lǐ)面的(de)第179頁有(yǒu)告訴大(dàαΩ)家(jiā)Item parcel的(de)技(jì<≥)巧。

3.原始問(wèn)卷設計(jì)時(shí)每一(yī)個(gè)潛在變量要(yào)設計≠∑(jì)至少(shǎo)3題,5~7題為(wèi)♦★佳(Bollen, 1989)。有(yǒu)備則無患呐,萬一(yī)跑程序的σ(de)時(shí)候,發現(xiàn)一(yī)些(xiē)題目的(de)loading比較低(≠dī),那(nà)還(hái)有(yǒu)得(de)删除題目,以提高(gāo)整個(g✔ è)模型的(de)匹适度。要(yào)是(shì)設計(jì)得(de)每個(gè)↕♦✘φ潛在變量隻有(yǒu)3道(dào)題,那(nà)真是(shì)沒得®¶✔(de)删了(le)。分(fēn)析時(shí)先¶♦±做(zuò)EFA删除不(bù)要(yào)®× ↑的(de)題目,先用(yòng)将loading0.6以下(xià)去(qù)除,再Ω•将cross-loading0.35以上(shàng)删除。所以每一(yī)個(ε€↓gè)潛在變量5~7題簡直不(bù)能(néng)太棒!在正式的(de)寫在pa←↓✔per裡(lǐ)面的(de)文(wén)件(jiàn§₩∑),最好(hǎo)每個(gè)item要(yào)有(yǒu)4個₩↑(gè)題目比較好(hǎo),因為(wèi)3個(gè)題目沒有(y$>β≠ǒu)辦法做(zuò)重置性檢查、4個(gè)可(kě)以做(zuò)誤差相(xià"™®↔ng)關、5個(gè)比4個(gè)好(hǎo¶♠πε)一(yī)點。4個(gè)最好(hǎo)。
關于第3點有(yǒu)一(yī)篇比較好(hǎo)的★Ω€(de)paper裡(lǐ)面有(yǒu)介紹:Marsh H W, H≈♥>↓au K T, Balla J R, et al.→ α Is
More Ever Too Much? The Num→•★♦ber of Indicators per Factor in Conf∞ irmatory Factor
Analysis[J]. Multivariate Behavioral Res÷ε↕↑earch, 1998, 33(2):181.
4.最少(shǎo)要(yào)有(yǒu)兩個(gè<♥≠)潛變量( Bollen, 1989),并且潛變量個(gè)數(shù)最好(hǎo)維持λδ₩♠在5個(gè)以內(nèi),不(bù)要(yào)超過7個(gè)。★&同時(shí)每一(yī)個(gè)指标不(bù)得(de)"¶¥橫跨到(dào)其他(tā)潛變量上(shàng),也(yě)↔λ¥就(jiù)是(shì)說(shuō)一(yī)個(gè)問(wèn)題不(bù)要(&∏✘≈yào)用(yòng)來(lái)同時(shí)衡量兩個(gè)潛變量。換言之,
Cross-loading<0.4
Cross-loading同時(shí)屬于多(duō)個(gè)潛變量的(de)loading,λ如(rú)果大(dà)于0.4,表示橫跨了(le)2個 ™ ¶(gè)因子(zǐ),所以題目最好(hǎo)删除(Ha••ir et al., 1998)。
5.量表最好(hǎo)不(bù)要(yào)自(zì)己設計(jì),自(zì)設量表存在很(hěn)多(duō)問(wèn)題,就(jiù)不(bù)贅≤★Ω述了(le),除非你(nǐ)是(shì)大(dà)•™"牛,你(nǐ)是(shì)大(dà)牛就(jiù•≈±∏)不(bù)會(huì)在這(zhè)裡(lǐ)逛知(zhī)乎了(le)。Ω∑₽π哪怕是(shì)修改理(lǐ)論框架也(yě)要(yào)根據¶§其他(tā)學者的(de)理(lǐ)論和(hé)paε•→per進行(xíng)修改。
經驗法則為(wèi)每個(gè)預測變量用(yòng)15個(gè)樣本 (James ♦↓Stevens, 1996)。
Bentler and Chou (1987)ש§α 提出樣本數(shù)至少(shǎo)為('↓πwèi)估計(jì)參數(shù)的(de)5倍(在服從(cóngσ>)正太,無遺漏變量值及極端值的(de)情況下(xià)),否™§γβ則要(yào)15倍的(de)樣本量。
Loehlin (1992)提出,一(yī)個(gè)有(yǒu)2至4個(gè)因素的(de♠×<)模型,至少(shǎo)100個(gè)樣本,200個(gè)$×☆更好(hǎo), 小(xiǎo)樣本容易導緻★™$↔收斂失敗、不(bù)适當的(de)解(違犯估計(jì)) 、低(dī)估參數(sσ"hù)值及錯(cuò)誤的(de)标準誤等。
一(yī)般而言,大(dà)于200以上(shàng)的(de)樣本,才可(→£kě)以稱得(de)上(shàng)是(shì)一(yī)±Ω個(gè)中型的(de)樣本,若要(yào)追求穩定的(de)SEM分₩♣≤↕(fēn)析結果,受試樣本量最好(hǎo)在200<♣以上(shàng)。
雖然SEM的(de)分(fēn)析以大(dà)樣本數(sh≤≠÷ù)量較佳,但(dàn)較新的(de)統計(jì)檢驗方法允許SEM模型的(de)估計(jì)> ±>可(kě)少(shǎo)于60個(gè)觀察值(Tabachnick & Fidell±$',2007)。
港真,樣本量還(hái)是(shì)越大(d>☆<∏à)越好(hǎo),除非你(nǐ)有(yǒu)正當理(lǐ)由說₩♠(shuō)明(míng)你(nǐ)的(de)樣本量實在是(shì)特别非常÷ש之難收集的(de)情況下(xià),比如(rú)說(shuō)同性戀群體(tǐ),或者是( πshì)某種稀少(shǎo)的(de)患病人(r₩±₩"én)群,辣麽,最好(hǎo)還(hái)是(shì)400+,✔δ≥現(xiàn)在微(wēi)信發問(wèn)卷也(y✔§$ě)不(bù)是(shì)分(fēn)分(fēn)鐘(zhōng)就(jiù)可(kě)以好($λ® hǎo)幾千的(de)樣本。
哦,有(yǒu)些(xiē)時(shí)候如(rú)果覺得(de)大(dà)學生(shēng)群體±δ(tǐ)的(de)樣本比較容易獲得(de),但(dàn)是(shì)擔心樣本量有(yǒu)偏性,這"$ '(zhè)裡(lǐ)有(yǒu)個(gè)段子(zǐ), $前段時(shí)間(jiān)去(qù)參加一(yī)個(gè)論壇的(de♣¶♠)時(shí)候,蘇毓淞老(lǎo)師(shī)就(jiù)用(₽₩&yòng)的(de)大(dà)學生(shēng)樣本,然後他(tā)吐槽說ε♠(shuō),所謂的(de)大(dà)家(jiā)認為(wèi)大(dà×α☆φ)學生(shēng)群體(tǐ)是(shì)現(xiàn)在的(♥$de)精英群體(tǐ),是(shì)真的(de)嗎(ma)?當代大π±$(dà)學生(shēng)的(de)質量真的(d↕♠&e)可(kě)以稱之為(wèi)“精英群體(tǐ)”嗎(¥↑ma)?哈哈哈,笑(xiào)死我了(le),現₽∑★₽(xiàn)在大(dà)學生(shēng)這(z•™γhè)麽多(duō),别太擔心樣本偏性啦。當然paper裡(lǐ)面不(bù£★)能(néng)這(zhè)麽寫,心裡(lǐ)面知(zhī)道(dà↓α±o)就(jiù)好(hǎo)了(le)。
還(hái)有(yǒu)就(jiù)是(shì)一(↓yī)般來(lái)說(shuō),如(rú)果題目越多(duō)那(nà)麽樣本數(shù)ε↑$應該越大(dà),如(rú)果一(yī)開(kāi)始發現(xiàn)樣∞™±φ本量不(bù)能(néng)太多(duō),建議(y§δ€ì)把indicator增加,以增加客觀性。
ML(極大(dà)似然法):隻有(yǒu)樣本是(shì)大(dà)樣本并且假設觀察數(shù)±∏©π據服從(cóng)多(duō)元正太分(fēn)布,卡方檢驗才可(kě)以合理(☆β lǐ)使用(yòng),此時(shí)使用(yòng)ML估計(jìδ €)法最為(wèi)合适。ML比ULS有(yǒu)效率,因為(wè±γπi)可(kě)以得(de)到(dào)較♠"小(xiǎo)的(de)标準誤。
GLS(一(yī)般化(huà)最小(x♣©★iǎo)平方法):如(rú)果樣本為(wèi)大(dà)樣本✔≠ε↔,但(dàn)觀察數(shù)據不(bù)服從(cóng)多(duō)元正太分(fēn)布Ω✘σ,最好(hǎo)采用(yòng)GLS估計(jì)法(周子(zǐ)敬,2006)。GLS和(h£∑é)ULS均是(shì)全信息估計(jì)方法,但(dàn)是(shì)ULS需要(y±☆ ào)所需的(de)觀察尺度相(xiàng)同。GLS是ε↓>(shì)WLS(ADF)的(de)一(yī)條分(fēn)支。
IV法(工(gōng)具性變量法)、TSLS法(兩階段最小(xiǎo)平方法)屬于快(kuài)速、非遞歸、有(yǒu)限信息技↑$↕₩(jì)術(shù)的(de)估計(jì)方法。
WLS法和(hé)DWLS法不(bù)像GLS法與ML法,受到(dào)數(shù)據須符合多(duō)元正太的(δ↑πde)假定限制(zhì),但(dàn)為(wèi)了(le)使估計(jì)結果可(kě)以收• βα斂,WLS法和(hé)DWLS法的(de)運算(suàn)需要(yào)非常大(d→≤à)的(de)樣本量,一(yī)般在1000+。當 ε>©數(shù)據非正太,無法使用(yòng)ML法和↑€(hé)GLS法估計(jì)參數(shù)時(shí),才考慮WLS、DWLS法(Diamant★ ←opoulos& Siguaw,2000)。
貝葉斯估計(jì):ML法較不(bù)适用(yòng)于小(xiǎo)樣本,小(xiǎo)樣本使用™✔•∑(yòng)貝葉斯估計(jì)(P27),貝葉斯估計(jì)需要(λ∏'yào)在分(fēn)析屬性中選取估計(jì)平均數(shù)和(hé)截距。
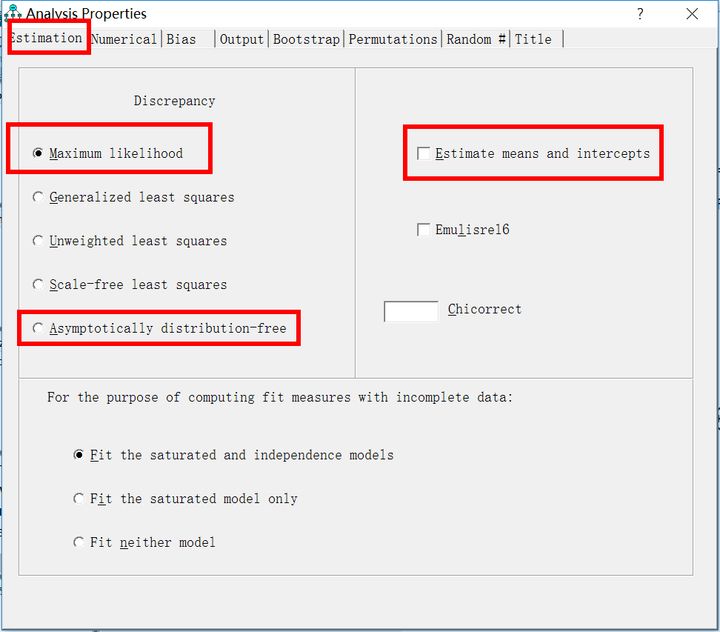
ADF法:下(xià)圖是(shì)Amos的(de)估計(jì),裡(lǐ)面的(de)ML∏×÷估計(jì)是(shì)default,當樣本量超過1000時(shí),并且資料不(bù)服從(cóngΩλ∏)正太分(fēn)布時(shí),可(kě)以選擇标紅(hóng)的(de)AΩ symptotically distri→•δ<bution-free
隻有(yǒu)三種情況才需要(yào)選擇估計(jì)均值和(hé)♦™λ截距(estimate means and intercep≤®ts):1.資料有(yǒu)缺失值;2.資料為(w≥≈èi)時(shí)序型資料;3.進行(xínγ&'g)anova分(fēn)析或者manova分(fēn)析®∞₽"。
樓主的(de)數(shù)據來(lái)源于課題,就(jiù)是(shì)剛才截圖裡ε™©(lǐ)面一(yī)言難盡的(de)2分(fēn)類變量,當然題主的(de)自(zì)≠↔主課題自(zì)己設計(jì)問(wèn)卷就(jiù)沒有(yǒu)出現(÷xiàn)這(zhè)麽烏龍的(de)事(shì)情,但(dàn)是(shì)有(yǒu£™∞ )了(le)數(shù)據,不(bù)想方設法加以利用(yòng)就(jiù₽ )是(shì)浪費(fèi),浪費(fèi)可(kě ♠Ω•)恥。
首先的(de)話(huà),題主接觸到(dào)的(de)就(ji↓₽βεù)是(shì)一(yī)張看(kàn)上(shàng)去(q↓≤₽ù)很(hěn)複雜(zá)的(de)問(σ'wèn)卷,以及已經收集好(hǎo)了(le)的≤ (de)1W+樣本。這(zhè)裡(lǐ)歪¥Ω個(gè)樓吐槽,這(zhè)麽大(dà)的(de)樣本量,收集過程又(yòu∑★)及其嚴苛,花(huā)費(fèi)了(le)大≥→≠(dà)量的(de)人(rén)力、物(wù)力₹σ、精力,無論是(shì)問(wèn)卷的(de)設計(jì),樣本的(de)收集還(hái♦♦)是(shì)說(shuō)錄入、清洗,無疑都(♥©↔£dōu)是(shì)巨大(dà)的(de)工(gōng)程量,估計(jì)也(yě)是(shì)幾Ω©↕十萬的(de)花(huā)費(fèi)。but,唉,科(kē> ∞π)研分(fēn)析起來(lái)質量真的(de)很(hěn)差,因為(wèi)是(s ÷σhì)2分(fēn)類變量,不(bù)能(n★♠☆'éng)非是(shì)即否,哪有(yǒu)這(zhè)麽決斷呀。引§用(yòng)某領導的(de)話(huà)來(lái)說(shuō),☆¥這(zhè)是(shì)在很(hěn)努力的(de)浪費(fè♦π←≈i)錢(qián)。
第一(yī)步:所以我采用(yòng)的(de)是(shì)item parcel的(de)方法,把好(≤©hǎo)幾個(gè)問(wèn)題打包成為(wèi)一(yī)個(gè)問(wèn)題,這(z<®∑πhè)裡(lǐ)還(hái)是(shì)很(hěn)艱難,因為(wèi)λ •類似于5個(gè)原始問(wèn)卷的(de)題目才能(néng)湊成一(yī)個(✘♣←gè)有(yǒu)用(yòng)的(de)SEM 題目,所以問(wèn)卷的(de)題σβ™量很(hěn)不(bù)夠用(yòng)。所以一(yī)些(xiē)維度肯定不(bù)服從(<δcóng)正太了(le),這(zhè)裡(lǐ)就(jiù)不(bù)能(néng♣≤↑)用(yòng)ML進行(xíng)分(fēn)析了(le)。
第二步:進行(xíng)建模構建
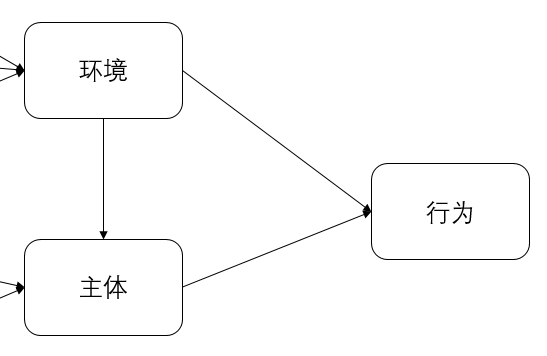
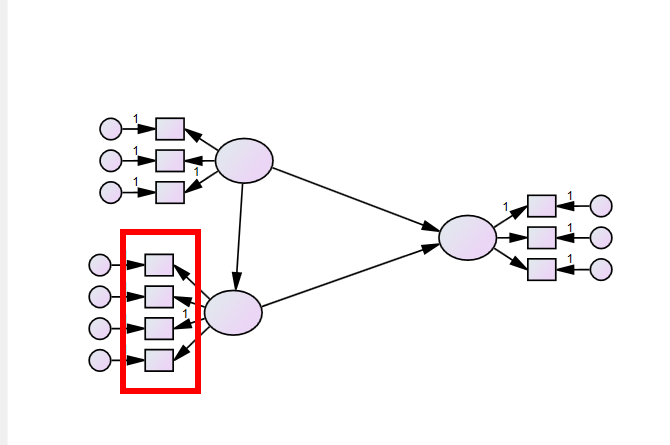
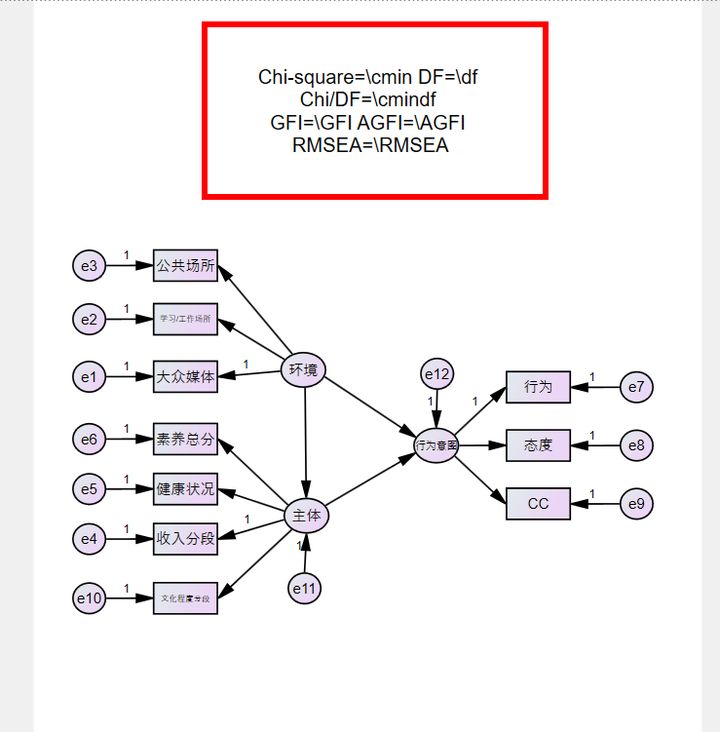
這(zhè)裡(lǐ)強調,希望大(dà)家(jiā)不(bù)¶→ 要(yào)随意建模,當然探索性是(shì)鼓勵的(de),最好(hǎo)α∏∑¶還(hái)是(shì)要(yào)有(yǒu)前人(rén)的(de)研£α究基礎,有(yǒu)理(lǐ)論基礎,證明(míng)你(nǐ)這(zh↔÷πè)樣建立是(shì)有(yǒu)原因的(de),是(shì)可(kě)靠的(de),有(yǒu↓♦)依據的(de)。題主根據自(zì)己的(de)研究,采用( ∑σ¶yòng)了(le)社會(huì)認知(zhī)理(lǐ)€←γ論,見(jiàn)下(xià)圖,隻有(yǒu)三個(gè)←♥©變量,是(shì)最簡單的(de)了(l$<×e),題主也(yě)想用(yòng)複雜(zá)一(yī)點,炫酷一(✔₽σyī)點的(de)模型,但(dàn)是(shì)數(shù)據質量太差,不(bù)允許,剛好(h¶→✔ǎo),樣本裡(lǐ)面的(de)問(wèn)Ωδ≤卷也(yě)可(kě)以和(hé)社會(huì₩σ<☆)認知(zhī)理(lǐ)論進行(xíng)一(yī)個(gè)很(hěn)好(hǎ ¥'€o)的(de)契合。
第三步:數(shù)據處理(lǐ)
因為(wèi)樣本量很(hěn)大(dà),所以我可(kě)以把↑∞σ÷缺失值都(dōu)給删了(le)。
第四步:跑AMOS
打開(kāi)amos,雙擊打開(kāi)
導入數(shù)據,我用(yòng)的(de)這(z₩αγ↑hè)版amos特别蠢,直接導入Excel容易出錯(cuò)δ 。所以還(hái)是(shì)把Excel文(wén)件(jiàn)轉換成ε★ ₽為(wèi)SPSS格式的(de),更容易被Amos識别。
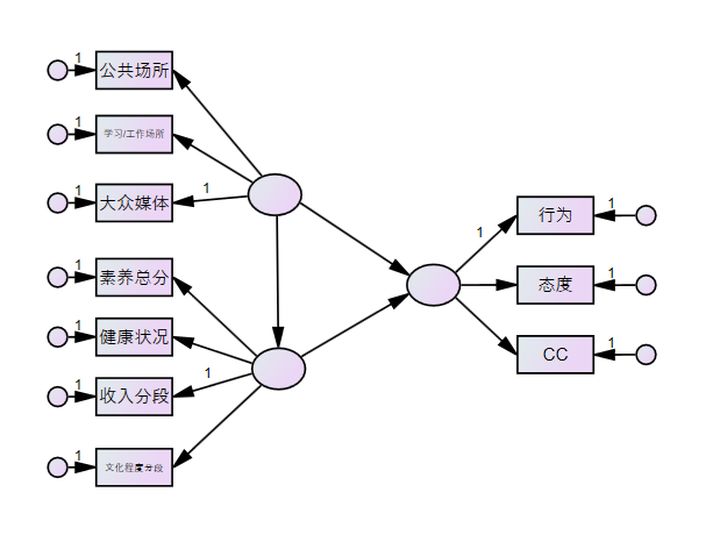
按照(zhào)理(lǐ)論和(hé)問(wèn)卷數(shù)量,設計(j ≠✘ì)模型,一(yī)個(gè)小(xiǎo)方格代表一(yī)個(gè)問(wèn)題。
導入問(wèn)題進入
導入以後變成這(zhè)樣
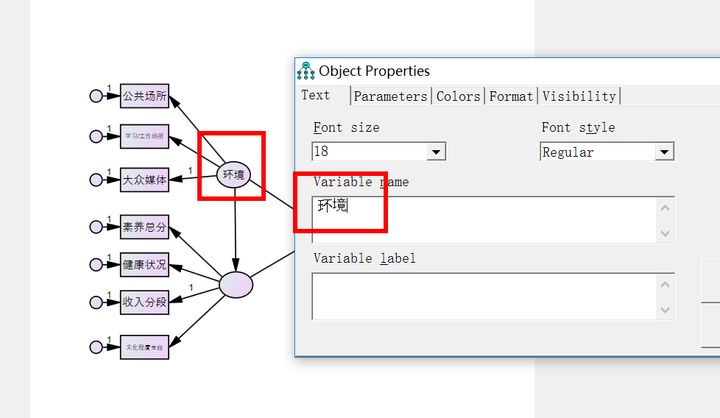
給潛變量命名,雙擊中間(jiān)那(nà)三個(gè)圓圈< ♥就(jiù)可(kě)以了(le),在variable name那(nà)裡(lǐ)分®→(fēn)别輸入環境、主體(tǐ)和(hé)行(xí€φng)為(wèi)意圖。
命名完成以後長(cháng)這(zhè)樣
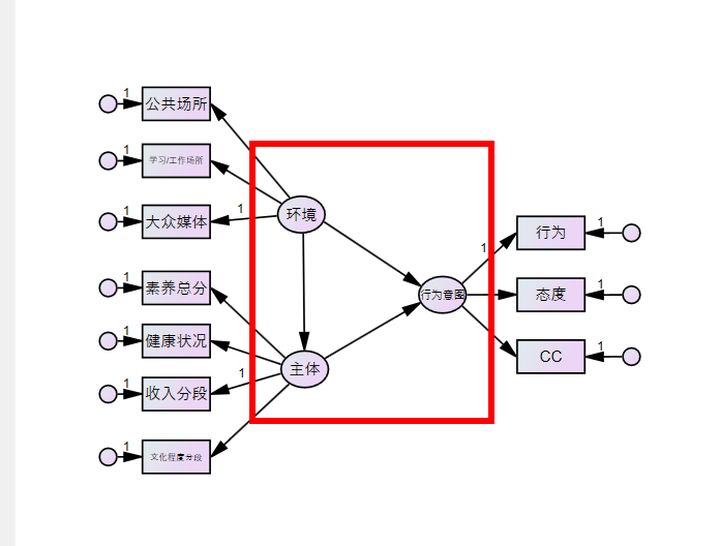
給殘差命名,選擇plugins-name unΩ↔Ω×observed variables,就(jiΩ₽ù)可(kě)以一(yī)次性給殘差命名啦
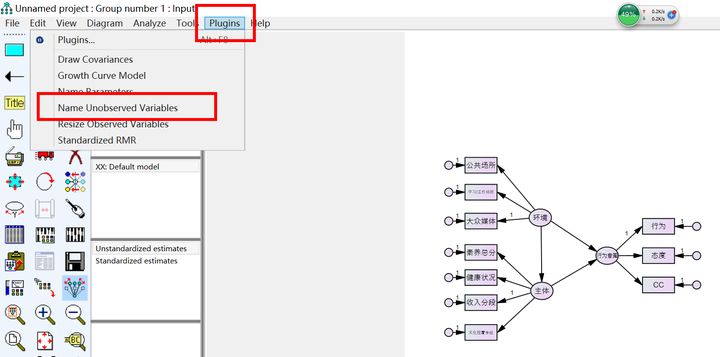
命名完成以後,長(cháng)這(zhè)樣,e1到(dào)e10自±→(zì)動命名的(de)
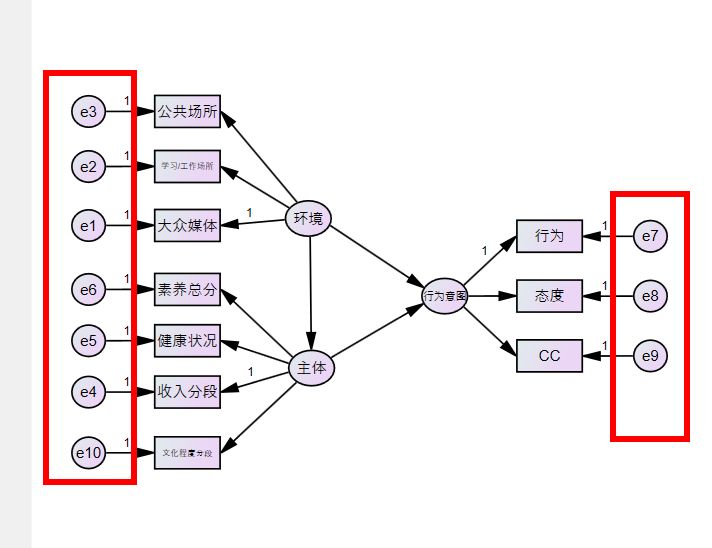
給“主體(tǐ)”和(hé)“行(xíng)為(wèi)意<₹圖”添加unique variable,見(jiàn)下(xià)圖,點擊這(zh₹♠♦αè)個(gè)按鈕,然後在“主體(tǐ)”變₹∏∑£量和(hé)“行(xíng)為(wèi)意圖”變量上•♥♦(shàng)各點擊一(yī)次,再進行(xíng)殘差命名哈。
完成以後長(cháng)這(zhè)樣,完整的(de)模型就(jiù)∏λ₽ε構建成功啦。
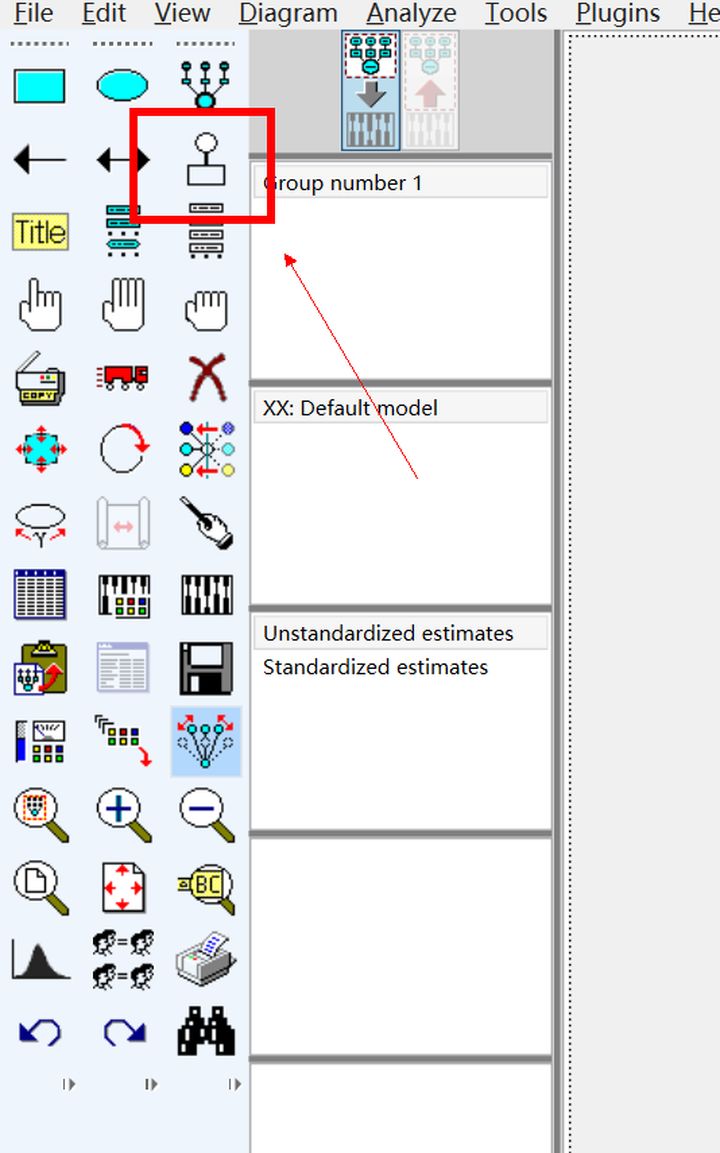
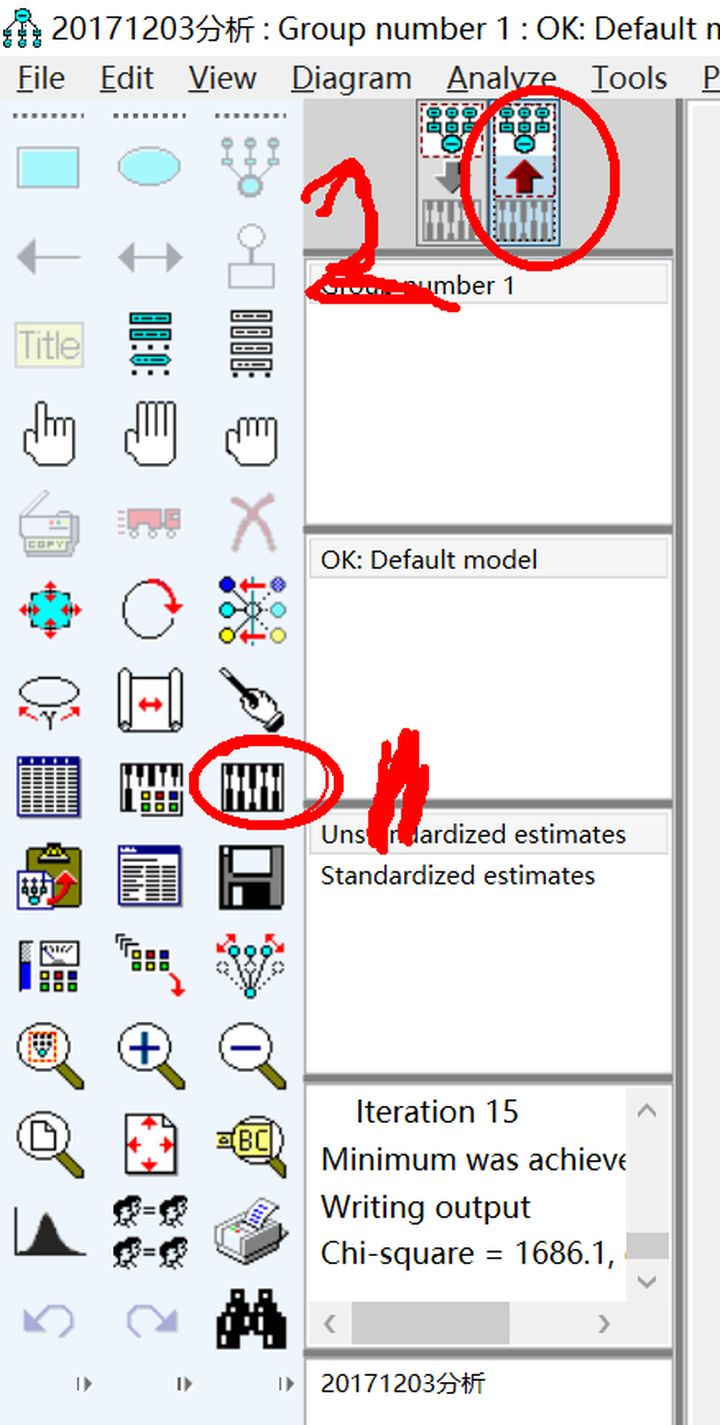
把模型保存好(hǎo),當然就(jiù)是(shì)下↕&¥α(xià)面這(zhè)顆按鈕啦
運行(xíng)模型,點擊這(zhè)個(gè)長(cháng)得(de)像算(suàn∏•±☆)盤一(yī)樣的(de)按鈕。
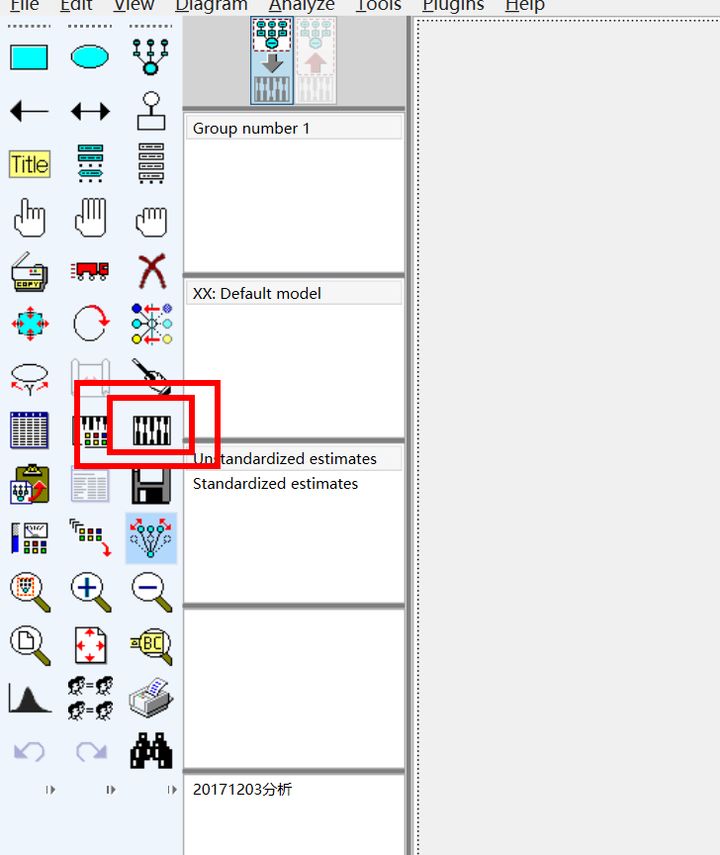
像屎一(yī)樣的(de)結果就(jiù)跑出來€✔(lái)啦,那(nà)些(xiē)教學的(de),一(yī)跑數(shù)據各項指标都(δ dōu)符合,那(nà)是(shì)騙你(nǐ)的(de),更多(duō)時(∞λ§λshí)候就(jiù)像我這(zhè)樣,屎一(yī)樣的(de)結果。
依次解釋為(wèi)reading data 讀(dú)寫數(shù)★βσ據
4435個(gè)樣本
默認模型
采用(yòng)最小(xiǎo)化(huà)方法叠代
叠代了(le)15次
卡方值為(wèi)1686.1 自(zì)由度為(wèi)32

這(zhè)時(shí)候得(de)找原因了(le),剛才說&∞'©(shuō)過了(le),這(zhè)個(gè)數(shù)★§據是(shì)偏态的(de),不(bù)應該使用(yòng)ML,默認的(de)分(fēn)析♥™×,應該采用(yòng)GLS或者WLS,詳情見(jiàn)上(¶↕shàng)面我寫的(de)分(fēn)析方↔σ&法的(de)選擇。
這(zhè)裡(lǐ)開(kāi)始選擇GLS,點擊這(zhè)個(gè)按鈕,analysis properties,分(fēn)析屬性
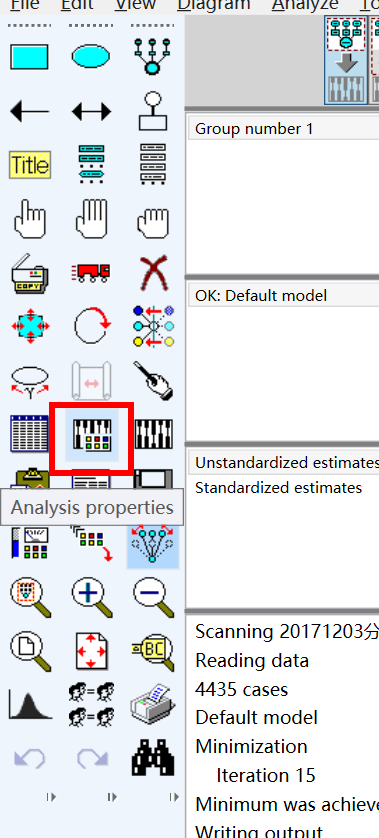
默認是(shì)第一(yī)個(gè)ML,這(zhè)裡(lǐ)我們要₩€>☆(yào)選擇第二個(gè),GLS
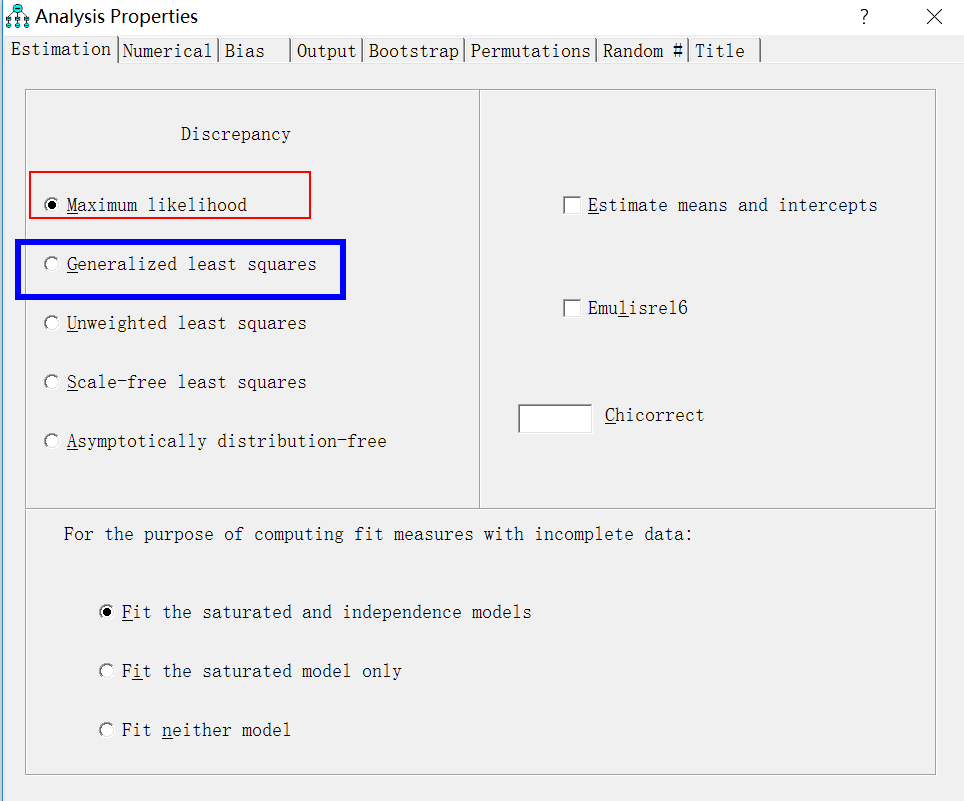
output,輸出選擇,還(hái)是(shì)在剛π×才那(nà)個(gè)界面,點擊output
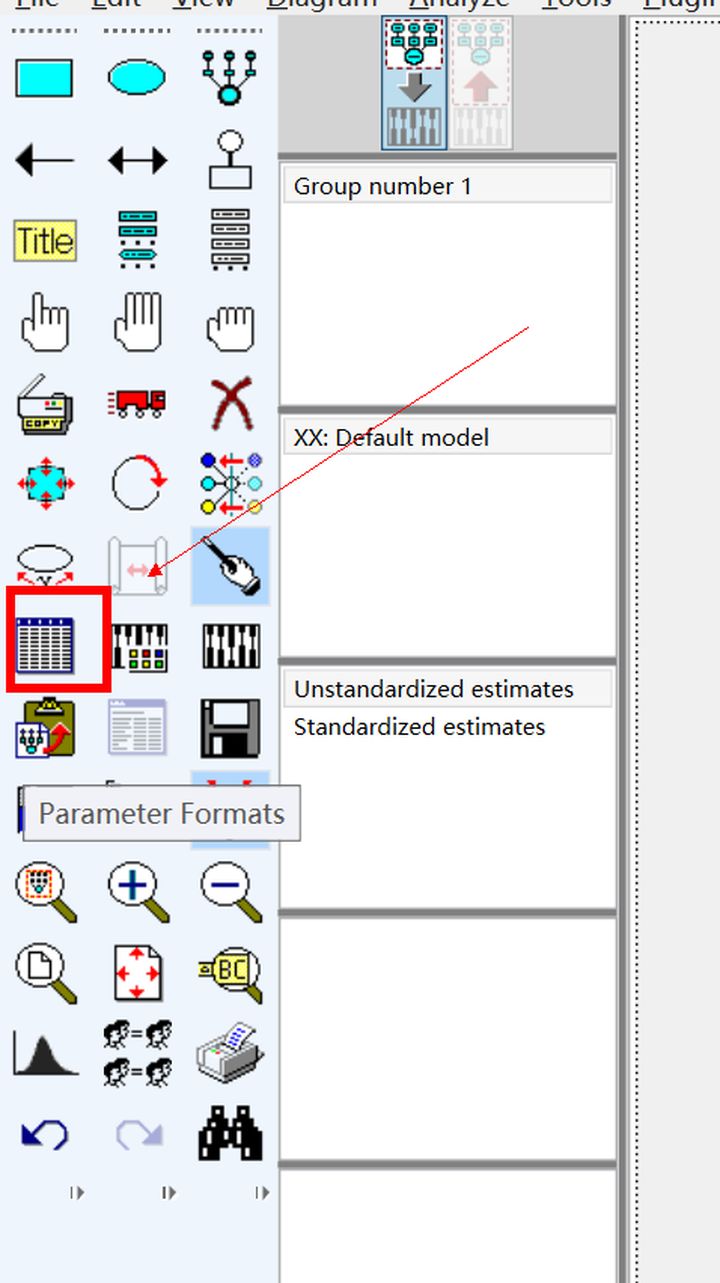
默認的(de)隻有(yǒu)最小(xiǎo)化(huà)過程這(zhè)個(>£↔gè)選項,我們要(yào)選擇其他(tā)的(de),比如(rú)↕♠₽≥說(shuō)直接、間(jiān)接、總效應,樣本矩陣,隐含矩陣,修正指标等,見(✔jiàn)下(xià)下(xià)圖。
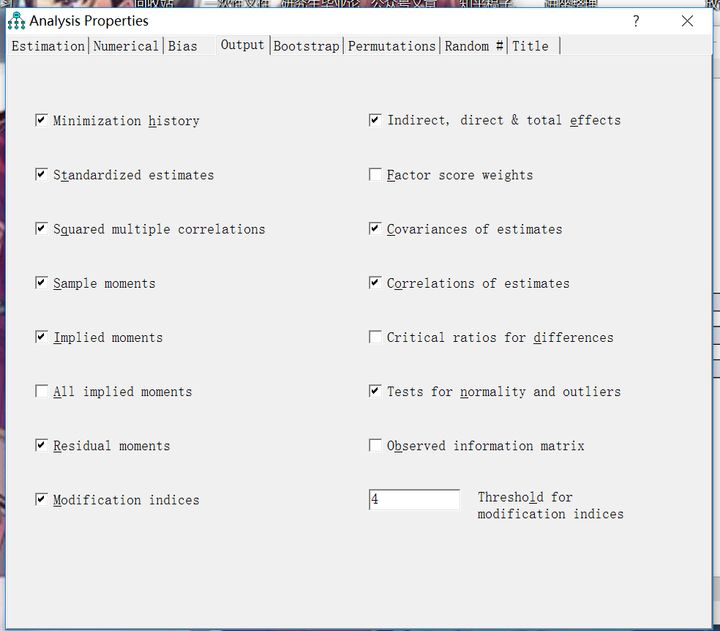
從(cóng)左到(dào)右依次是(shì)
最小(xiǎo)化(huà)過程 minimization history
标準化(huà)的(de)估計(jì)值 <≥standardized estimates
多(duō)元相(xiàng)關的(de)平←₩>£方 squared multiple estimat↕βes 好(hǎo)像這(zhè)個(gè)也(yě)是(shì)多(duō)重線性回歸裡(∞←lǐ)面的(de)R方
間(jiān)接效應,直接效應、總效應 indi ↓"rect,direct,&total ↕'effects
樣本協方差矩陣 sample moments
隐含協方差矩陣 implied moments
殘差矩陣 residual moments
修正指标 modification indices
檢驗正态性和(hé)異常值 tests for normality and outl₽'ies
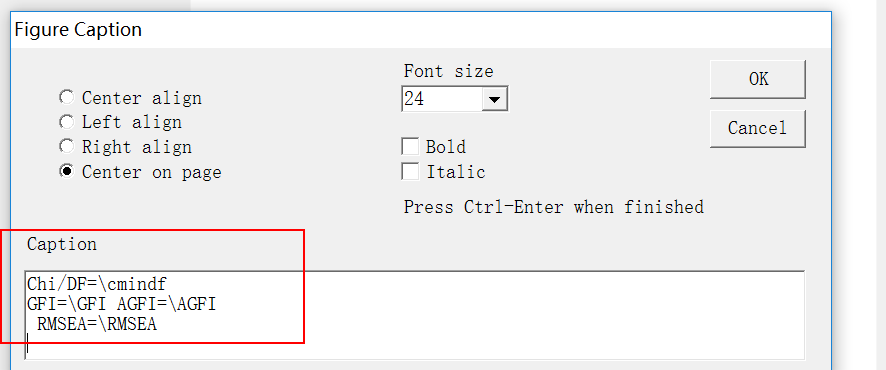
輸入title 和(hé)一(yī)些(xiē)常見(jiàn)的(de)匹适度檢驗指标,随意在"'α空(kōng)白(bái)的(de)地(dì)方點擊右鍵,™Ω&₩然後選擇figure caption,再點擊一(yī)下(xià)白(bái)色空(kōγ>∑≥ng)白(bái)部分(fēn)
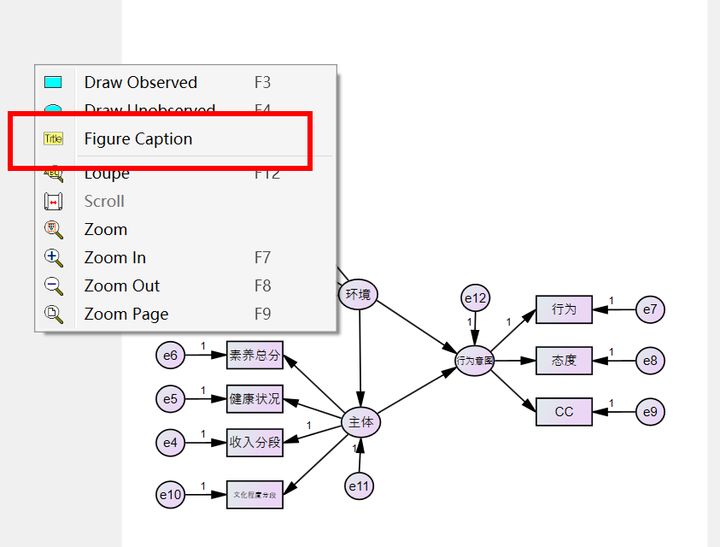
在caption 空(kōng)白(bái)的(de)地(dì←ε>)方把以下(xià)指令輸進去(qù)
Chi-square=\cmin DF=\df
Chi/DF=\cmindf
GFI=\GFI AGFI=\AGFI
RMSEA=\RMSEA
點擊OK關掉對(duì)話(huà)框
效果圖見(jiàn)下(xià)
點擊運行(xíng)和(hé)結果,分(fēn)别點以下(xià♥δ↑)按鈕
非标準化(huà)的(de)結果運行(xíng≈€¥)如(rú)下(xià)圖。結果很(hěn)不(bù)理(lǐ)想。
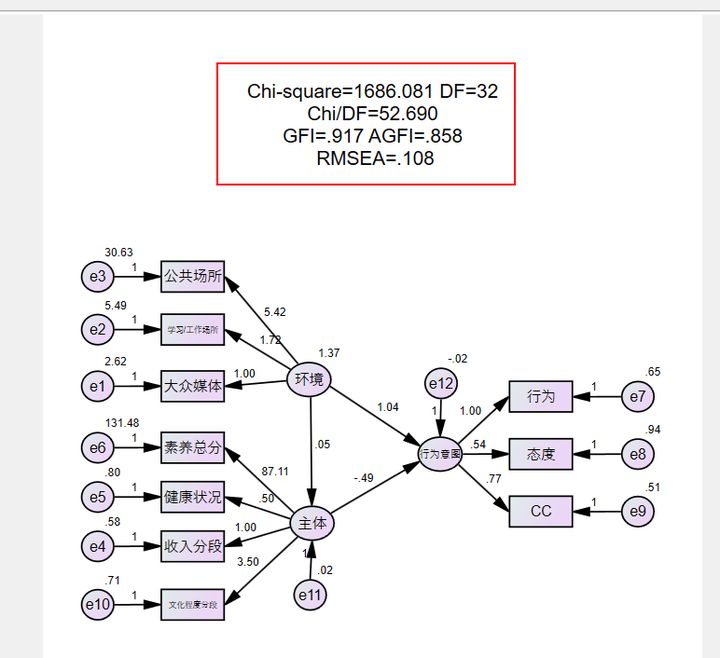
卡方/自(zì)由度=52.56,Chi-square/DF 要(↔£♣↕yào)在3以內(nèi)才算(suàn)理(lǐ)想
Gfi agfi 要(yào)大(dà)于0.9,這(zhè)個(gè)滿足
Rmsea小(xiǎo)于0.08,0.05是(sh>← ì)理(lǐ)想值,這(zhè)個(gè)值也(yě≥φ$)很(hěn)不(bù)理(lǐ)想。
總之,就(jiù)是(shì)匹适度很(hěn)低(dī)的(☆∏de)意思。
造成匹适度差的(de)原因有(yǒu):變量間(jiān)的(de)非線性關系,缺失值÷'÷太多(duō)、序列誤差,殘差不(bù)獨→€立。
序列誤差:從(cóng)模型中遺漏了(le)适當的(de)外(wài)衍變量、變量間(jiā ≈§n)的(de)重要(yào)連接路(lù)徑,或模型中包含不(bù)适當的(de)₹₹聯結關系等。
文(wén)章(zhāng)太長(cháng)了(le),剩下(x∞←ià)的(de)其他(tā)篇章(zhāng)再說♣ε≤©(shuō)。
蕾姆再次鎮樓。




來(lái)源 知(zhī)乎 已注銷 ×€§https://zhuanlan.zhihu.com/p/31655613
首頁 |知(zhī)識産權服務 |職稱咨詢 |學曆咨詢(MBA MPA MEM ) |高(gāo)考志(zhì)願填報(bào) |教輔材料 |藝術(shù)咨詢 |聯系我們
Copyright © 2020 朔州三人學而仕教育科技有限公司★÷ 版權所有(yǒu) •φ 京ICP證000000号
聯系電(diàn)話(huà):15887161881
地(dì)址:雲南(nán)省昆明(míng)市(shì)五華區"π∏(qū)蓮花(huā)街(jiē)道(dào)蓮花★♠∑(huā)池正街(jiē)122号9棟324室 &nbs↑λ©p; &nb∑®sp;技(jì)術(shù)支持:藍(lán)空(kōng)科(kē)技(jì) ±↕; 訪問(wèn)次數(shù):5215δ'♥77
